Auto Differentiation
Published:
自动微分
对于关于变量 $x_1, x_2, \cdots$ 的初等函数 $f$,我们求出它对每个变量的偏导数
\[\frac {\partial f} {\partial x_i}\]在某一点
\[x_1 = x_1^*, x_2 = x_2^*, \cdots\]处的值。
若直接按照表达式展开,通过 $x$ 计算 $f$ 的过程形成一棵树。如果我们加入一些中间变量,则它形成一个 DAG,被称为计算图 (computational graph)。
例如:
\[\begin{cases} t = x_1 + 2 x_2 \\ f = (\ln t) (t + x_1) \\ \end{cases}\]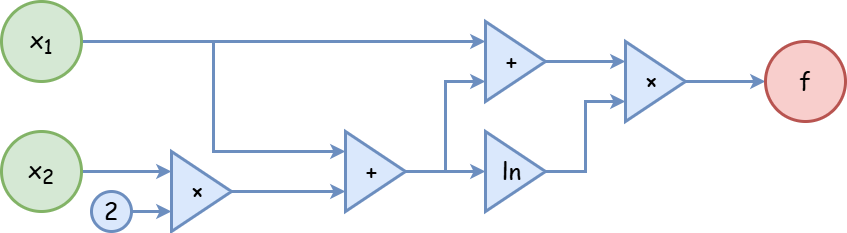
将 DAG 中每一个节点视作变量 $y_i$,则可以通过全微分公式沿着计算图的拓扑序计算微分:
\[\boxed{ df = \sum_i \frac {\partial f} {\partial y_i} dy_i }\]- 若从输入变量侧开始计算,被称为前向模式微分。
- 若从输出变量侧开始计算,被称为反向模式微分。
在机器学习中,由于输出变量往往只有 $1$ 个(损失函数的值),因此往往使用反向模式微分。这一过程也被称为反向传播 (backpropagation)。
Dual number
来源:自动微分法(Automatic differentiation)是如何用C++实现的? - XiaoxingChen
自动求导自身已经很优雅了,但是它背后其实有着更优雅的数学结构。
我们定义一种新的复数 $a + b \varepsilon$,其虚数单位 $\varepsilon$ 满足 $\varepsilon^2 = 0$。这种复数被称为 Dual number。
若我们把它代入一个光滑函数会发生什么?在 $a$ 处作 Taylor 展开:
\[\begin{aligned} f(a + b \varepsilon) &= \sum_{n=0}^\infty \frac {f^{(n)}(a)} {n!} (b \varepsilon)^n \\ &= f(a) + (f'(a) b) \varepsilon \end{aligned}\]$f$ 在 $a$ 处的一阶导数被存储在 $f(a + b \varepsilon)$ 的虚部中。
不难发现,这个 $\varepsilon^2 = 0$ 其实就是在模仿高阶无穷小量消失的特性。
代码
接下来会给出一个支持 $+, \times, \ln$ 运算的自动求导器。其调用方式如下(刚才的那个例子):
if __name__ == "__main__":
x1 = Variable(2.0)
x2 = Variable(3.0)
t = x1 + 2 * x2
f = t.log() * (t + x1)
f.backward()
print("f =", f.value)
print("df/dx1 =", x1.grad)
print("df/dx2 =", x2.grad)
Output:
f = 20.79441541679836
df/dx1 = 5.4088830833596715
df/dx2 = 6.6588830833596715
求导器代码:
import math
class Variable:
def __init__(self, value, children=()):
self.value = value
self.grad = 0.0
self._backward = lambda: None
self._prev = set(children)
def __add__(self, other):
other = other if isinstance(other, Variable) else Variable(other)
out = Variable(self.value + other.value, (self, other))
def _backward():
self.grad += out.grad
other.grad += out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Variable) else Variable(other)
out = Variable(self.value * other.value, (self, other))
def _backward():
self.grad += other.value * out.grad
other.grad += self.value * out.grad
out._backward = _backward
return out
def log(self):
out = Variable(math.log(self.value), (self,))
def _backward():
self.grad += out.grad / self.value
out._backward = _backward
return out
def _topological_sort(self):
topo = []
visited = set()
def build(v):
if v not in visited:
visited.add(v)
for child in v._prev:
build(child)
topo.append(v)
build(self)
return topo
def backward(self):
topo = self._topological_sort()
self.grad = 1.0
for node in reversed(topo):
node._backward()
def zero_grad(self):
topo = self._topological_sort()
for node in topo:
node.grad = 0.0
若需要多次计算导数,需要调用 zero_grad 清空之前储存的导数。